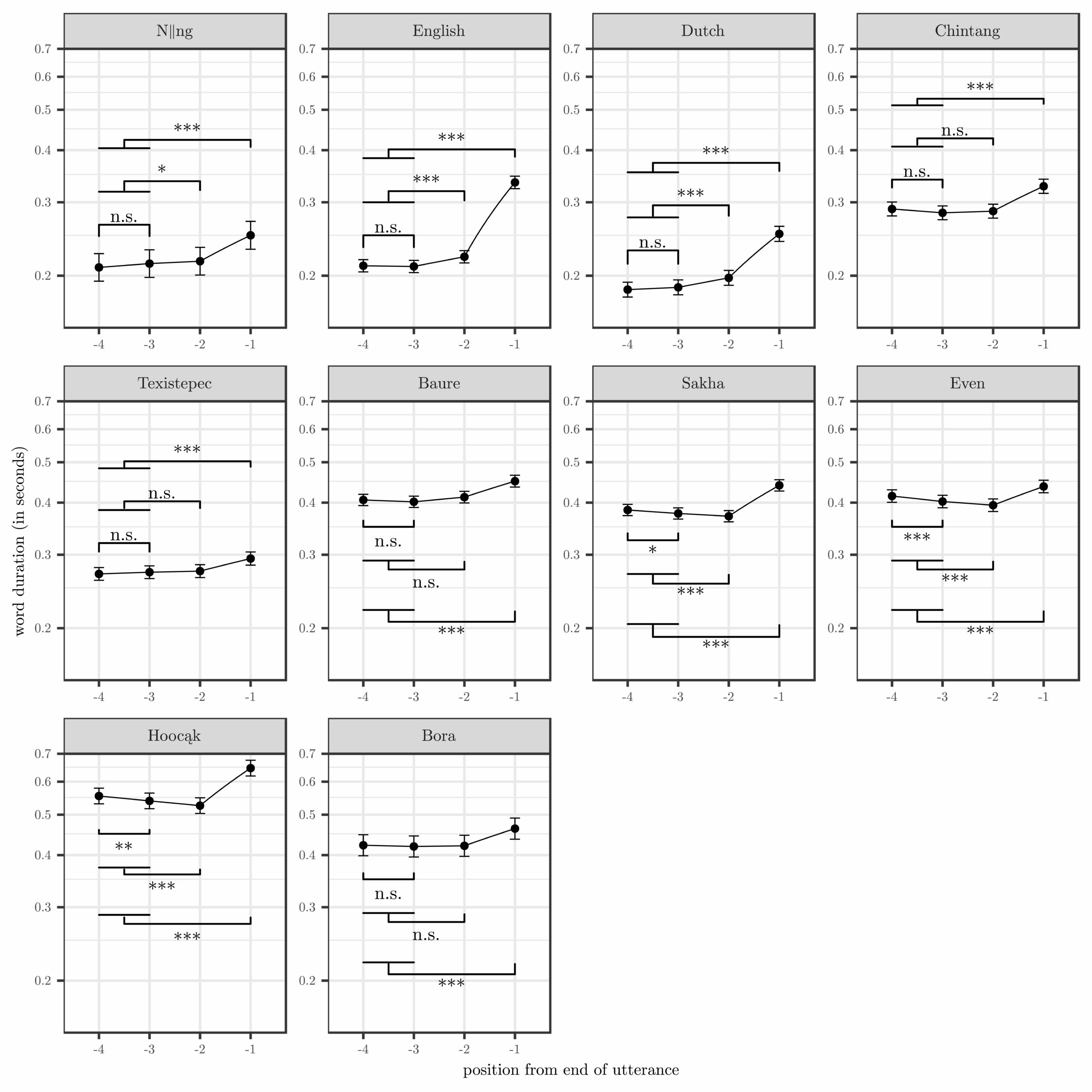
Matthew Stave’s presentation on morphological typology was awarded the prestigious award for the best presentation by a PostDoc at this year’s Societas Linguistica Europaea (SLE) conference. The paper analyses 19 DoReCo corpora testing correlations between morphological characteristics associated with ‘agglutinating’ vs. ‘inflecting’ languages. Stay tuned for the write-up of this study!
Matthew Stave, Kilu von Prince & Frank Seifart. 2021. A usage-based approach to morphological typology. Paper presented at the Societas Linguistica Europaea (SLE) 2021. Workshop 14: Integrating sociolinguistics and typological perspectives on language variation, 30 August – 3 September 2021, online.